Переменные и объекты в Python
Конспект посвящён переменным в Python: как они устроены, чем отличаются от переменных в других ЯП и т.д., а также интернированию, неизменяемым и изменяемым типам данных, поверхностному и глубокому копированию.
Начнём с того, что в Python нет переменных. По-крайней мере в том виде, в котором они представлены в более низкоуровневых ЯП, таких как C или C++. Вместо этого в Python — имена. Разберёмся, в чём здесь разница.
Переменные в C и C++
|
|
Исполнение вышележащей строки проходит через три этапа:
- Выделение достаточного количества памяти для числа;
- Присвоение этому месту в памяти значения 101;
- Отображение, что
numуказывает на это значение.
Упрощённо это можно представить следующим образом:
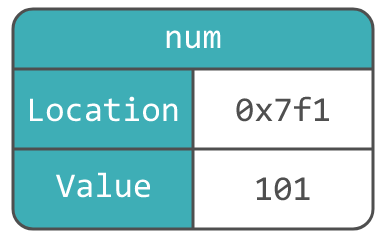
Здесь переменная num имеет виртуальный адрес 0x7f1 и значение 101. Если позднее нам захочется изменить значение, это можно сделать так: int num = 102;.
Этот код присваивает переменной num новое значение 102, тем самым перезаписывая предыдущее значение. Это означает, что переменная изменяема. Обновлённая схема памяти для нового значения:
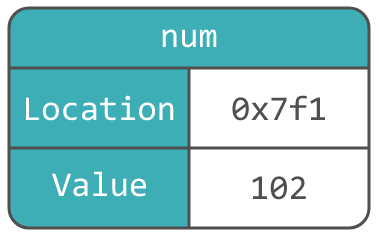
Расположение переменной в памяти не поменялось, но поменялось значение, а значит num — место в памяти, а не просто имя.
Если мы выполним следующий код: int num1 = num;, мы получим уже две абсолютно разные области памяти, с различными адресами (хоть и одинаковым значением).
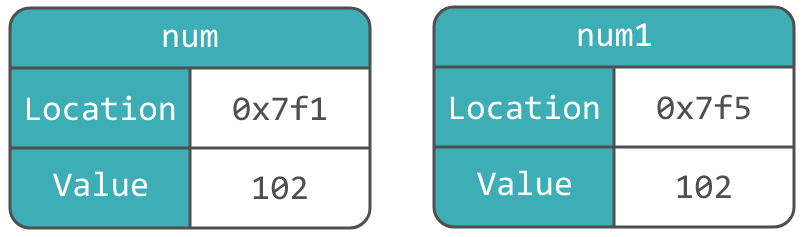
С переменными в Python ситуация другая.
Переменные в Python
В Python нет переменных, как таковых, вместо них имена. Вполне допустимо использовать термин переменные, однако важно понимать разницу.
Напишем тот же код на Python: num = 101.
Исполнение также происходит в несколько этапов:
- Создаётся специальный объект
PyObject; - Заполняется его поле
Type, которое указывает на тип; - Заполняется его поле
Value, которое указывает на значение; - Создаётся имя
num; - Имя
numначинает указывать на созданныйPyObject; - Счётчик ссылок (поле
Reference Count) объектаPyObjectувеличивается на 1.
Можно представить себе это следующим образом:
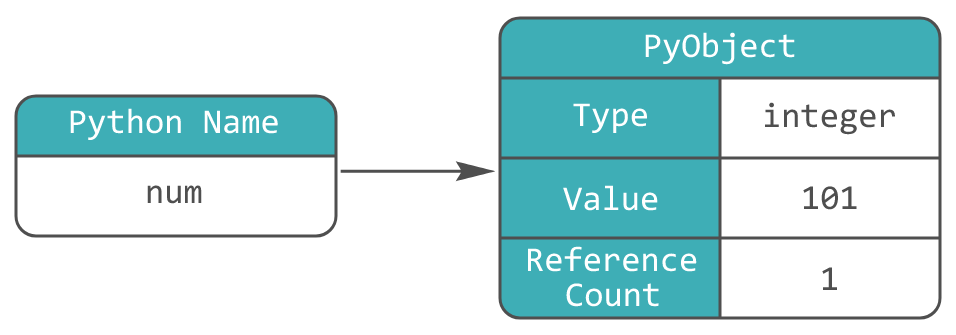
Как видно, схемы памяти для Python и C/C++ отличаются. Вместо того, чтобы num владел блоком памяти, в котором хранится значение 101, num ссылается на участок памяти, которой владеет PyObject объект.
Присвоим переменной новое значение: num = 102. Исполнение этой строки кода также проходит через несколько этапов:
- Создаётся новый
PyObject; - Заполняется его поле
Type, которое указывает на тип; - Заполняется его поле
Value, которое указывает на значение; - Имя
numуказывает на новыйPyObject; - Счётчик ссылок (поле
Reference Count) новогоPyObjectувеличивается на 1; - Счётчик ссылок (поле
Reference Count) старогоPyObjectуменьшается на 1.
Взглянем на новую схему памяти:
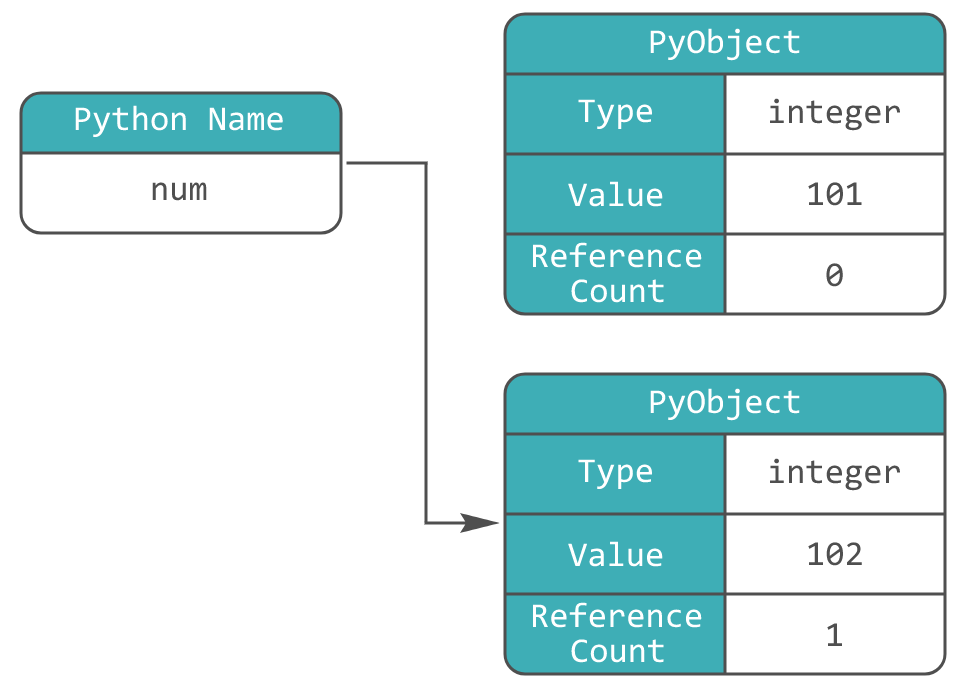
Изображение демонстрирует, что переменная привязалась к новому объекту и отвязалась от предыдущего. К тому же PyObject, содержащий значение 101, теперь имеет счётчик ссылок, равным 0, а значит будет уничтожен сборщиком мусора (GC).
Введём новую переменную (имя): num1 = num. В памяти не появится нового объекта, новое имя будет ссылаться на уже существующий (счётчик ссылок которого будет увеличен на 1):
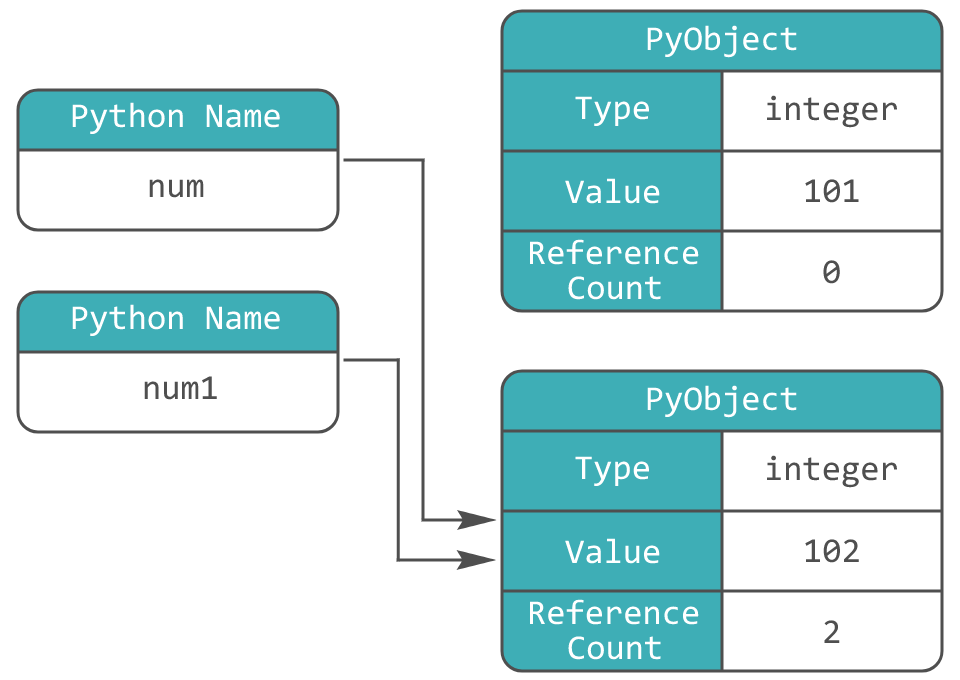
Важно также отметить, что структуры данных, ровно как имена, содержат указатели на объекты. Допустим, у нас есть список nums = [1, 2, 3]. В нём не хранятся сами значение, а хранятся указатели на них, а сами объекты 1, 2 и 3 содержатся в других областях памяти.
Адрес объекта
У каждого объекта в Python есть собственный идентификатор, который устанавливается только один раз при его создании. Идентификатор объекта – это целое и постоянное число, которое никогда не изменяется после его создания. В стандартной реализации Python (CPython) идентификатор объекта ассоциируется с адресом объекта в памяти. Для того чтобы получить идентификатор объекта, используется встроенная функция id().
|
|
|
|
При каждом новом запуске id будут разные, так как заранее не устанавливается, какое значение будет в определённым участком памяти. Таким образом, объекты, периоды существования которых не пересекаются, могут иметь одинаковый id.
Если объекты изменяемые, то в большинстве случаев они будут иметь разные идентификаторы. Например:
|
|
|
|
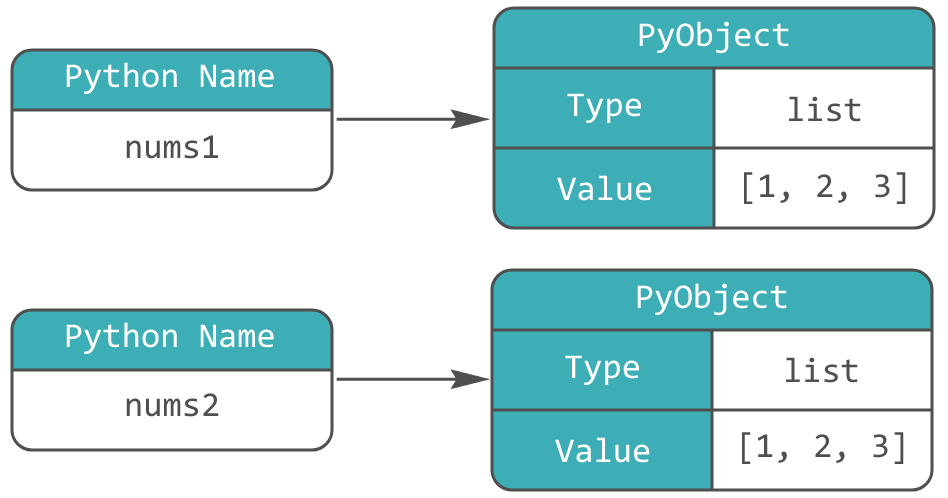
== сравнивает объекты поэлементно, а не по idПолучаем, что переменные nums1 и nums2 указывают на разные адреса памяти, хоть и имеют одинаковое содержимое.
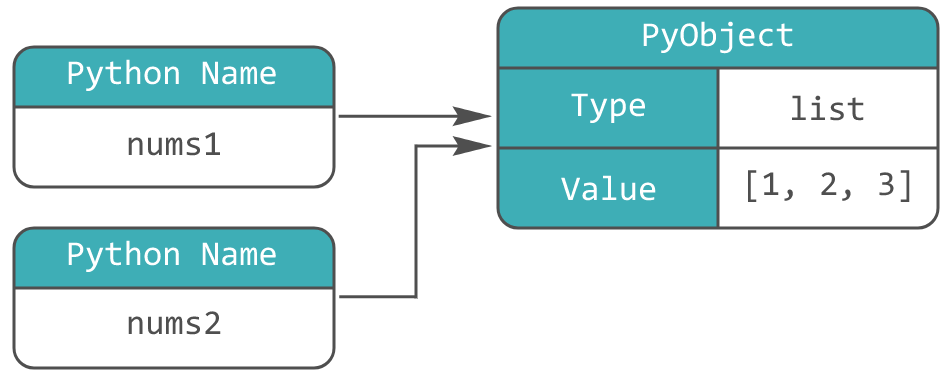
Нужно также помнить, что оператор присваивания =, никогда не создает копию данных, а, скорее, привязывает имя к объекту. Следующий код будет выводить одинаковые id:
|
|
|
|
None, True, False и другиеОператор is
С помощью оператора is можно сравнить id объектов:
|
|
|
|
Для проверки значения на равенство с None обычно используют is:
|
|
Интернирование объектов
Как мы знаем, в Python целые числа (тип int) и строки (тип str) являются неизменяемыми. Это значит, что после того как строковые и целочисленные объекты были созданы, мы не можем изменить или обновить их. Даже если кажется, что строка изменяется, например, после использования метода, на самом деле создается новая строка, а исходная остается прежней.
Учитывая неизменяемость строковых и целочисленных объектов, Python использует специальную оптимизацию, которая называется интернированием. Интернирование — это процесс хранения в памяти только одной копии объекта. Это означает, что, когда мы создаем две строки (два целых числа) с одинаковыми значениями, то вместо выделения памяти для них обоих, только одна строка (целое число) фактически фиксируется в памяти. Другая же просто указывает на то же самое место в памяти. Для реализации данной оптимизации Python использует специальную таблицу, которая называется пул интернирования. Эта таблица содержит одну уникальную ссылку на каждый объект строкового типа, либо целого числа.
Основные преимущества интернирования:
- Экономия памяти: мы не храним копии одинаковых объектов;
- Быстрые сравнения: сравнение интернированных строк происходит намного быстрее, чем неинтернированных строк. Это происходит потому, что для сравнения интернированных строк нужно только сравнить, совпадают ли их адреса в памяти, а не сравнивать их содержимое.
Интернирование целых чисел
Python интернирует целые числа в диапазоне [-5; 256]. Если мы наберём следующий код в IDLE:
|
|
получим такой результат:
|
|
Но среда, в которой пишется код, может самостоятельно указывать диапазон интернирования. Так, в VS Code, тот же самый код вернёт:
|
|
Интернирование строк
В Python 3.7 интернируются строки, содержащие не более 20 символов и состоящие только из ASCII-букв, цифр и знаков подчёркивания. Данный набор символов был выбран потому, что он часто используется в нашем коде.
|
|
|
|
Добавим символ ! в строку:
|
|
|
|
Начиная с Python 3.8 длина интернируемых строк была увеличена до 4096 символов.
|
|
|
|
Как я понял, VS Code применяет свои правила интернирования и для строк, а конкретно интернирует любую последовательность символов длинной до 4096 включительно.
Функция sys.intern()
Как мы уже знаем, Python интернирует лишь строки, содержащие не более 4096 символов и состоящие только из ASCII-букв, цифр и знаков подчёркивания. Однако функция intern() из модуля sys позволяет интернировать любую строку, например, содержащую 5000 символов или состоящую из букв русского алфавита. Данная функция принимает в качестве аргумента строку, добавляет ее в пул интернирования (если ее там нет) и возвращает интернированную строку.
|
|
Изменяемые и неизменяемые типы данных
Типы данных в Python делятся на две категории:
- изменяемые (mutable) —
list, set, dict, ...; - неизменяемые (immutable) —
int, float, bool, tuple, str, ....
Если мы попытаемся изменить, например, строку, то получим ошибку:
|
|
В то же время мы запросто можем изменить список:
|
|
Присваивание vs “мутация”
В Python есть два вида изменения объектов:
- Присваивание переменной нового объекта
- Мутация (непосредственное изменение) самого объекта
Слово “изменение” зачастую носит двусмысленный характер. Фраза “мы изменили x” может означать “мы переназначили x”, а может означать “мы мутировали объект, на который указывает x”.
Например, следующий код повторно связывает имя с совершенно новым объектом: x = x + 1 (адрес num изменился). Но такая операция как num.append(7) добавляет элемент в уже существующий объект, то есть num указывает всё на тот же объект (адрес num не изменился).
+= в Python реализована через значение x. Эти две строки эквивалентны: x += y и x = x.__iadd__(y)Таким образом, если несколько имён ссылаются на один изменяемый объект, и программист модифицирует этот объект, изменения отразятся в каждом из имён:
|
|
|
|
Важно понимать, что со списками операции x = x + y и x += y работают по-разному. В первом случае, как мы уже знаем, создаётся новый объект, но при += модифицируется существующий список:
|
|
|
|
Причина такого поведения в том, что список реализует __iadd__ следующим образом:
|
|
То есть такой код: nums1 += nums2, эквивалентен: nums1.extend(nums2).
Модуль copy
Для использования: import copy.
Как мы уже знаем, оператор присваивания в Python не создает копию объекта, он лишь связывает имя переменной с объектом. Для создания реальных копий объектов в Python используют модуль copy.
Модуль copy содержит две функции:
copy(): копирует объект и возвращает его поверхностную копию;
deepcopy(): копирует объект и возвращает его глубокую копию.
Разницу между этими видами копирования можно проследить только для коллекций.
Поверхностное копирование
Поверхностное копирование создает отдельный новый объект, но вместо копирования дочерних элементов в новый объект, оно просто копирует ссылки на их адреса памяти.
|
|
|
|
Как видно, id объектов, как и их содержимое, различаются, так как элементами списка являются целые числа, поэтому изменение одного списка не отражается на другом. Если бы элементами списка были бы изменяемые типы, то поверхностное копирование скопировало бы лишь ссылки на их адреса памяти. Следовательно, любое изменение элементов одного объекта отразилось бы также и на элементах другого объекта.
В следующем коде видно, что изменения затронули оба списка, потому что оба они содержат ссылки на один и тот же вложенный объект. Так работает поверхностное копирование:
|
|
|
|
У списков, словарей и множеств есть собственный метод copy(), создающий их поверхностную копию:
|
|
Поверхностную копию также можно создать, используя соответствующие функции для каждой коллекции (list, dict, set, ...):
|
|
Ещё поверхностную копию списка можно сделать через срез: new_data = data[:]
Глубокое копирование
Глубокое копирование создаёт копию составного объекта рекурсивно. Это означает, что любые изменения, внесенные вами в новую копию объекта, не будут отражаться в исходной, и наоборот.
|
|
|
|
Основной источник: https://stepik.org/lesson/624529/step/1?unit=620219
Дополнительные источники:
 cloudtips
cloudtips